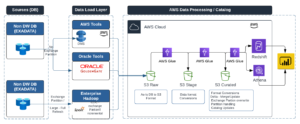
Data replication – accelerator to replicate complex tables and build AWS S3 Data Lake
Various DB Replication tools support replicating existing and ongoing changes to another database. Multiple challenges are involved in replication depending on the source DB Table complexity if the Target system is a file system – for example, AWS S3. Unfortunately, there are no tools in the market to address the following replication challenges, which require a custom solution.
I have built a data framework to address the below challenges to help real-time replication from Hadoop and large Tables (Exadata) to AWS to build a Data Lake on AWS.
Target System – AWS S3 – Challenges
- Target System – AWS S3 – Challenges – merging the target files, format conversions, data consistency, lock mechanism, etc.
- Ensuring the quality of data format during replication, and data consistency throughout the replication process
- Updating data catalog, synchronizing changes across other business/accounts
- Change management of table definitions
Source DB Challenges:
- Source table – has partitions and partition refresh
- The data change rate on Source DB is faster than the relevant data replication/transfer rate of changes to the target System.
- Identifying the CDC at Source if the source has files, table refresh, partition refresh, time series data